

Elevating Data Quality and Insights with a Cloud-Native Analytics Pipeline
Project Information
Client Representative Clients
Partnered with Programmatic B2B, LLC
Date Augast 2025
Case Study Elevating Data Quality and Insights with a Cloud-Native Analytics Pipeline
Overview
With over 25 years of experience in the B2B marketing sector, we have worked closely with a diverse range of clients. Beyond the usual marketing discussions, many of these clients shared their challenges with us—struggling to manage vast amounts of disparate data coming from multiple departments within their organizations. Their staff were often overwhelmed, spending countless hours manually cleaning, organizing, and reconciling data while coordinating with sales, production, and other teams. The constant pressure to deliver accurate, timely analyses to the board for critical decision-making only magnified the risk of manual errors and delays.
It was during these conversations that a clear idea emerged: why not develop a solution that could eliminate this cumbersome manual work? A product designed to automate data processing, improve accuracy, and streamline collaboration—helping not only us but all businesses facing similar challenges. One of our core motivations has always been to bring machine and man together, harnessing the strengths of both to create something truly great. This case study explores how that vision became a reality, driving efficiency and empowering users to make faster, more informed decisions.
The Problem
Each dataset required a huge amount of time to clean, merge, and validate, which caused significant delays in delivering actionable data. This impacted the team’s ability to make proactive decisions based on current information. The manual processes introduced challenges that affected overall efficiency and growth:
- Frequent errors due to inconsistent data formats, which reduced report accuracy
- Delayed insights that hindered timely responses to business trends
- Scalability limitations as growing data volumes increased the manual workload and slowed operations
The Hypothesis
Implementing a serverless, cloud-native analytics pipeline brought significant improvements to operations by automating data cleaning and structuring, providing live dashboards for real-time insights, and enabling self-service analytics for business users. This approach helped reduce errors, save time, and allowed operations to scale effectively. Key benefits included:
- Automated workflows that streamlined data preparation and minimized manual intervention
- Real-time dashboards that empowered users with up-to-date insights for faster decision-making
- Self-service capabilities that increased accessibility and reduced dependency on specialized teams
- Enhanced scalability ensuring efficient handling of growing data volumes while reducing errors and minimizing operational overhead
Test / Implementation
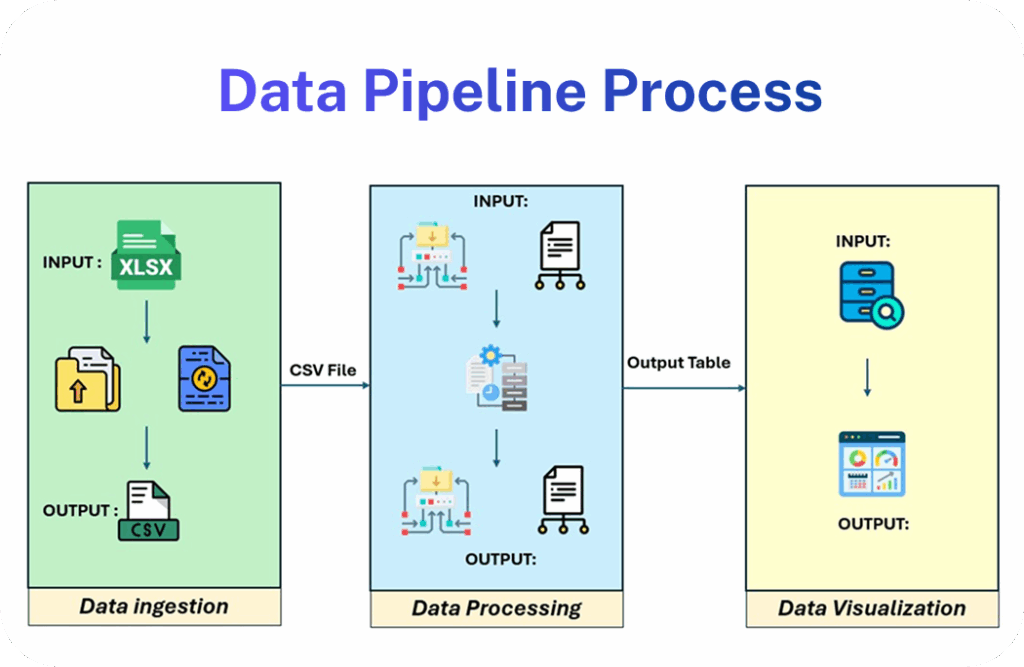
To validate this approach, a pilot was launched focusing on the following implementation steps:
- Secure file uploads through a simple, user-friendly interface
- Automated workflows to clean and structure incoming data
- Automated workflows to clean and structure incoming data
- Performance monitoring to track accuracy, processing speed, and user adoption
During the pilot, the team could upload datasets, watch them process automatically, and immediately access insights—all without manual intervention. This demonstrated the system’s practical application in streamlining data intake, processing, visualization, and performance tracking.
Results
The pilot achieved rapid, tangible improvements that significantly enhanced operational efficiency and data-driven decision-making:
- Dramatic time savings with data preparation cut from over 8 hours to under 15 minutes
- Significant accuracy gains achieved by reducing reporting errors to nearly zero, reaching 99% accuracy
- Enhanced accessibility enabling business users to independently explore insights without relying on IT support
- Optimized cost efficiency through streamlined cloud operations, maintaining average costs around $40 per month
- Robust scalability with a cloud architecture that effortlessly handles increasing data
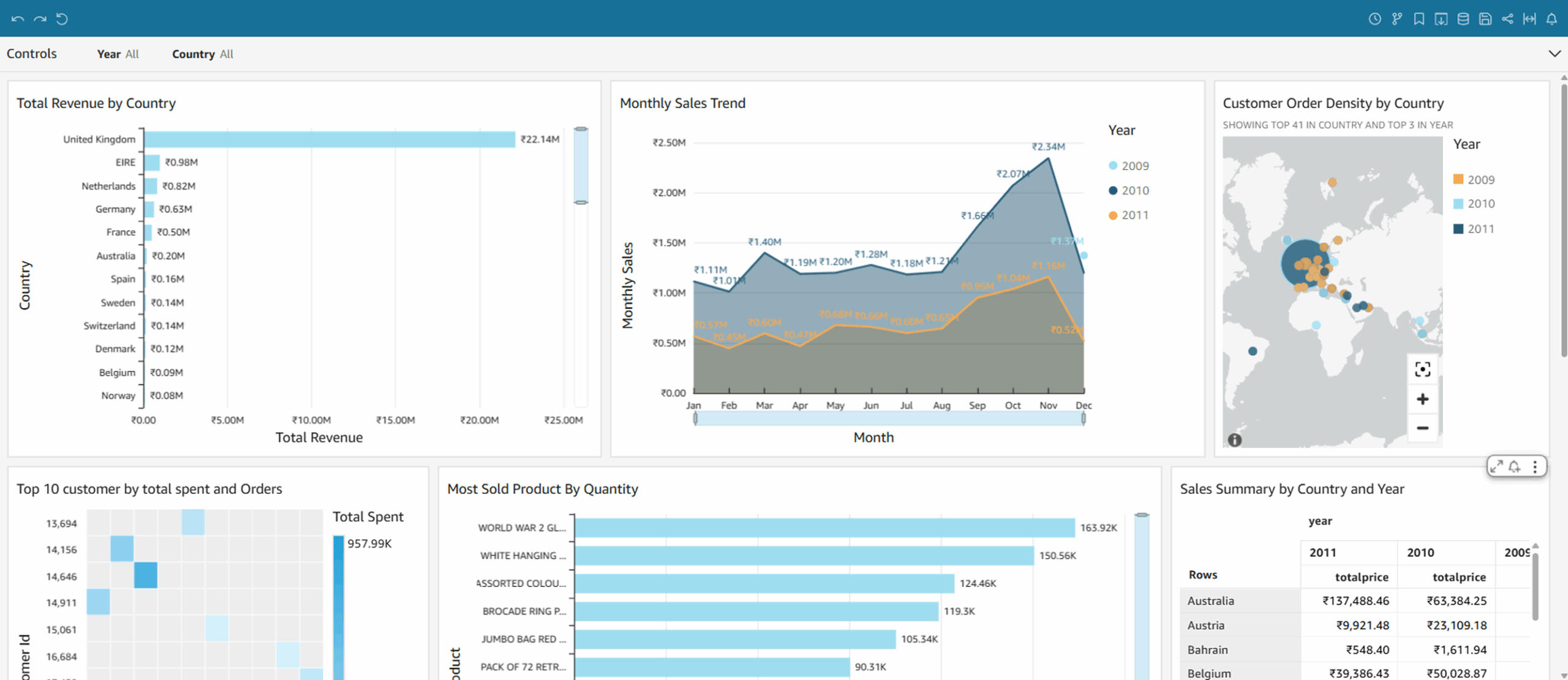
Conclusion
By implementing a serverless, cloud-native analytics pipeline, the client revolutionized their data management process. What once took teams hours now takes just minutes, with reporting errors reduced to almost zero and real-time insights readily available. This solution has boosted efficiency and accuracy while empowering business users to independently explore data and make faster, smarter decisions. Additionally, the scalable cloud infrastructure ensures the system can effortlessly accommodate growing data volumes as the organization expands.
Conclusion
By implementing a serverless, cloud-native analytics pipeline, the client revolutionized their data management process. What once took teams hours now takes just minutes, with reporting errors reduced to almost zero and real-time insights readily available. This solution has boosted efficiency and accuracy while empowering business users to independently explore data and make faster, smarter decisions. Additionally, the scalable cloud infrastructure ensures the system can effortlessly accommodate growing data volumes as the organization expands.
| Label | Value |
|---|---|
| File Size (MB) | 30 |
| Files per Day | 5 |
| Days per Month | 30 |
| Crawler DPU-Hours per run | 0.08 |
| Job DPU-Hours per run | 0.35 |
| DPU Cost (USD/hour) | 0.44 |
| Step Function Cost/run (USD) | 0.000025 |
| Average File Size (MB) | 50 |
Monthly Estimate
| Crawler Cost | 3.168 |
| Job Cost | 13.86 |
| Step Functions Trigger Cost | 0.00375 |
| Total Monthly Cost | 17.03175 |